返回目录:word文档
大家好,今天我们学习【机器学习速成】之深入了解机器学习。
视频教程:
课程讲义:
我们马上学三点,
- 直线拟合知识
- 将机器学习中的权重和偏差,与直线拟合中的斜率和偏移关联起来。
- 训练和损失

机器学习
1. 直线拟合知识
正如我们之前介绍的, 我们通过研究数据得到了模型。 复杂的模型类型有很多, 我们用来研究数据的有趣方法也有很多。 但我们先从最简单、最熟悉的方法入手, 这能帮助我们了解更复杂的方法。
让我们以数据为基础, 用第一个小模型练习一下。
这里有一个小型数据集, X轴是输入特征,显示的是房屋大小; Y轴是我们尝试预测的目标值房价。 我们来试着制作一个模型, 将房屋大小作为输入特征, 预测房价作为输出特征。

线性回归
在我们的数据集中,有很多用标签标出的小样本。 我们引导机器画一条线, 它查看我们的数据集后, 绘制一条直线来近似地表示房屋大小和房价的关系。 这条线就是一个模型, 根据给定的输入值预测房价。
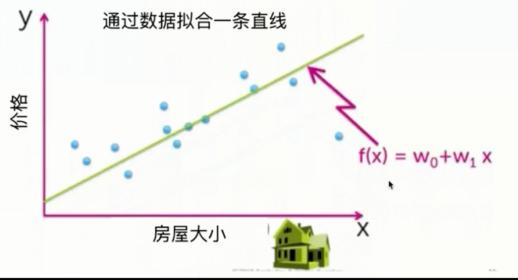
线性回归
我们如何知道这条线是正确的呢?
这时我们可能需要考虑损失这一概念, 损失从本质上反映了这条线在预测任何给定样本时的效果如何。 因此,我们可以通过观察给定X值的预测结果与相应样本真实值之间的差异, 来确定具体损失。 我们看到,有些损失适中,有些损失几乎为零,有些损失可能为正, 但是损失始终处于零到正数的范围之内。
2. 将机器学习中的权重和偏差,与直线拟合中的斜率和偏移关联起来。
事实上,虽然该直线并未精确无误地经过每个点, 但针对我们拥有的数据,清楚地显示了房屋大小和房价之间的关系, 我们将机器学习中的权重和偏差,与直线拟合中的斜率和偏移关联起来。
用直线方程表示上面的这条直线。
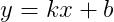
直线方程中:
- y 指的是房价,即我们试图预测的值。
- k 指的是直线的斜率。
- x 指的是房屋大小,即输入特征的值。
- b 指的是 y 轴截距。
按照机器学习的惯例,需要写一个存在细微差别的模型方程式:
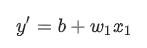
模型方程式中:
- y' 指的是预测标签(理想输出值)。
- b 指的是偏差(y 轴截距)。而在一些机器学习文档中,它称为w0。
- w1 指的是"特征1"的权重。权重与上文中用k表示的“斜率”的概念相同。
- x1 指的是特征(已知输入项)。
要根据新的房屋面积x1预测房价y',只需将 x1 值代入此模型即可。
下标(例如w1和x1) 预示着可以用多个特征来表示更复杂的模型, 如图三个特征的方程式:
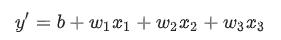
举例:大学课程的成绩一般由三个特征构成,平时出勤成绩x1,期中成绩x2,期末成绩x3。 每个特征有自己的权重。
3. 训练与损失
训练模型表示通过有标签样本来学习所有权重和偏差的理想值。 在监督式学习中, 机器学习算法通过检查多个样本,并尝试找出可最大限度地减少损失的模型; 这一过程称为经验风险最小化。
损失是对糟糕预测的惩罚。 也就是说,损失是一个数值, 表示对于单个样本而言模型预测的准确程度。 如果模型的预测完全准确,则损失为零,否则损失会较大。 训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。
如图,红色箭头表示损失,蓝线表示预测, 左侧显示的是损失较大的模型,右侧显示的是损失较小的模型。
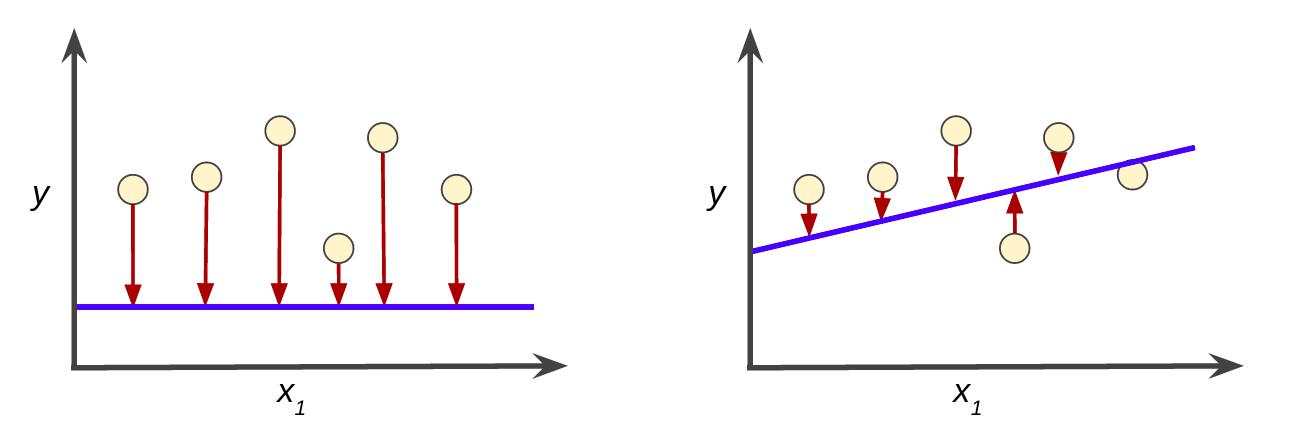
训练与损失
我们注意到, 左图中的红色箭头比右图中的对应红色箭头长得多。 显然,相较于左图中的蓝线,右图中的蓝线代表的是预测效果更好的模型。
我们能否创建一个数学函数(损失函数),以有意义的方式汇总各个损失。
平方损失
接下来我们要看的线性回归模型使用的一种称为“平方损失”的损失函数,也称为 L2损失。 单个样本的平方损失, = 预测值和标签值之差的平方; = (观察值 - 预测值)的平方; = (y - y')的平方;
很明显,离真实值越远,损失就会以平方数增加。 如今,我们在训练模型时, 并非专注于尽量减少某一个样本的损失, 而是着眼于最大限度地 减少整个数据集的损失。
均方误差
均方误差 (MSE) ,指的是每个样本的平均平方损失。 要计算均方误差,请求出各个样本的所有平方损失之和, 然后除以样本数量:
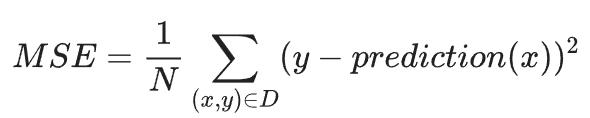
均方误差 (MSE)
其中: x 指的是模型进行预测时使用的特征集(例如,房屋大小)。 y 指的是样本的标签(例如,房价)。 prediction(x) 指的是权重和偏差与特征集x结合的函数。输入x就可以得到预测值 N 指的是数据集D的样本数量。
损失函数为什么用平方形式?
一个重要原因是:误差的平方形式是正数。 这样正的误差和负的误差不会相互抵消。 这就是为什么不用一次方,三次方的原因。
但是,误差的绝对值也是正的,为什么不用绝对值呢。 所有还有第二个重要原因是:平方形式对大误差的惩罚更大。
此外,还有第三个重要原因:平方形式对数学运算也更友好。 我们经常要求损失函数的导数,平方形式求导后变成一次函数; 而绝对值形式对求导数学运算很不友好,需要分段求导。
此外,4次方,6次方,8次方虽然也能避免误差正负相抵消, 但对大误差的惩罚又过大了;此外,求导后也仍然是多次函数。
总结:
线性回归是一种找到最适合一组点的直线或超平面的方法。 机器学习中的权重和偏差,与直线拟合中的斜率和偏移相关联 线性回归中常用的损失函数是均方误差。
这里讲了三点,关键词有哪几个?欢迎回复评论