返回目录:excel表格制作
原创作者 :林策@招聘技术 58招聘技术团队
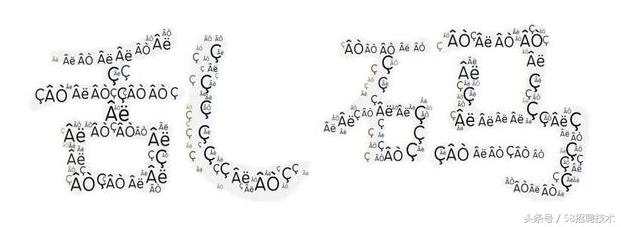
乱码问题对于咱们程序猿(媛)来说,可谓是抬头不见低头见,除了爹妈就他亲了。前段时间,小编在编码问题上遇到个过不去的坎,研究解决后和大家分享下。
一、啥是乱码?
下图这是同一文件以两种不同编码方式加载的结果,显然,左边就是我们常说的“乱码”。

记得某位大V说过,世界上本无乱码,说的人多了,也就成了乱码。
在小编看来,更贴切的说法应该是“编码/解码错误的字符”,他们都是有规律可寻的,大多时候我们都只看到他凌乱的外表,却没有理解其单纯的内心。只要对这些字符正确的编码及解码,他们都会回到我们熟知的样子。
二、基本概念
在口算修复乱码之前,先一块复习下几个概念:(内容较多,优秀的你可以直接跳到乱码?不乱一节)
字符集&字符编码
编码&解码
ASCII码
GBK系列
UTF-8系列
1、字符集&字符编码
字符集:一个系统支持的所有抽象字符的集合。
字符编码:在符号集合与数字系统之间建立的映射关系,是一种对应法则。
常见的字符集有以下几种:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。通常来说,一种字符集对应一种字符编码,但也有例外,比如Unicode字符集,对应的字符编码就是UTF-32,UTF-16和大名鼎鼎的UTF-8。
2、编码&解码
编码:将源对象内容(文字、符号等)按照一种标准转换为一种标准格式(数字编码)内容。
解码:编码的逆过程,它使用和编码相同的标准将编码内容还原为最初的对象内容(文字符号)。
这么说有些抽象,举个例子:
在一个GBK编码的文件中,有个“码”字,那么在存储时,就会将其用GBK编码,保存为“C2EB”。当你打开文件时,又用GBK对其解码,就展示为之前的“码”字了。聪明的你会问了,打开文件时如果用其他解码方式怎么办呢?这还用问么,当然是“乱码”啊,接着往下看就明白了。
3、ASCII码
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符。
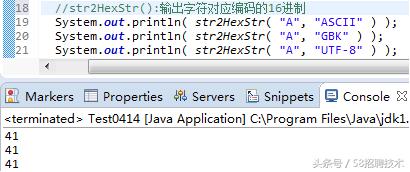
ASCII码是正式投入计算机使用的第一种编码,也是后起之辈GBK,UTF-8等等编码的鼻祖,因此在后续发展的所有编码中,对于ASCII码中出现的字符都保持了一致。代码为证:
4、GBK系列
当计算机传入天朝之后,原先的127个字符显然不能满足需求,于是本着自己动手丰衣足食的原则,勤劳勇敢的中华人民设计了属于自己的字符集和字符编码:GB2312。
GB2312:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,高字节从0xA1用到 0xF7,低字节从0xA1到0xFE,这样就能组合出多达6000多个简体汉字了。
聪明的你肯定想说,博大精深的中华文化哪里是6000个字能覆盖到。于是,后来陆续推出了GBK和GB18030,其中GB18030收录汉字70244个,而且采用多字节编码(每个字可以由1个、2个或4个字节组成,这里不深究)。
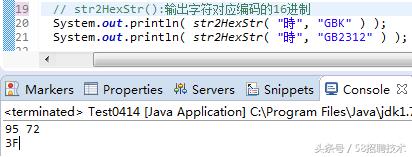
GB2312与GBK对中文字都是双字节编码。对于常见中文字,GB2312就够了,但仍有很多时候会出现无法识别的情况,代码为证(GB2312对无法识别的字符默认转化成3F,对应字符“?”,是不是很熟悉):
5、UTF-8系列(敲黑板,划重点!)
像天朝一样,每个国家都有其独有字符。为了解决不同国家各设计一套字符集的问题,Unicode编码诞生了,它为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字。每个数字代表唯一的至少在某种语言中使用的符号。
Unicode对应编码方式有三种:UTF-8,UTF-16,UTF-32,这里主要介绍UTF-8。
UTF-8:使用1字节/2字节/3字节/4字节表示字符。前128个等同于ASCII码,1字节表示。带附加符号的拉丁文、希腊文等用2字节表示。其他基本多文种平面(BMP)中的字符(这包含了大部分常用汉字)使用3字节编码。其他极少使用的Unicode辅助平面的字符使用四字节编码。
为了更直观的表示编码转换过程,这里简单介绍下UTF-8编码规则:
| Byte1 | Byte2 | Byte3 |
| 0 xxxxxxx | ||
| 110 xxxxx | 10 xxxxxx | |
| 1110 xxxx | 10 xxxxxx | 10 xxxxxx |
三、乱码?不乱!
有了以上知识储备,编码修复也就迎刃而解了。所有的乱码都是由于选取的编码或解码方式不合适造成,下面小编将举个例子来说明。
GBK——>UTF-8:"鎷涜仒"
这三字一看就是乱码,我们使用GBK编码与UTF-8解码来修复。
GBK编码映射结果为:
| 鎷 | E68B |
| 涜 | 9BE8 |
| 仒 | 8198 |
是按照:E68B 9BE8 8198 四个一组来做拆分
通过上面介绍可知,中文字符在UTF-8中是通过三字节进行编码的,我们将三个字的GBK编码按照每三字节为一组重组可得:
E68B9B
E88198
这两个字符代表什么呢?查询UTF-8编码表:
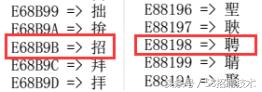
哦,原来是“招”“聘”!代码验证下:
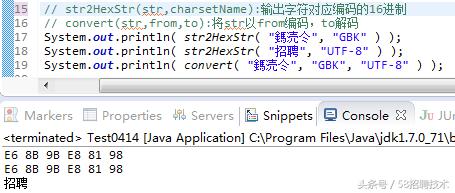
果然,“鎷涜仒”的GBK编码和“招聘”的UTF-8编码完全一致。
聪明的你肯定又要说,小编你是有多闲,这种东西查下就好了。没错,但当小编查询“招聘”2字的编码时,出现的是下面这玩意:
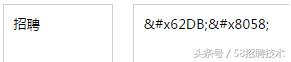
“62DB”是什么鬼?不是说好对应“E68B9B”的么?不着急,我们慢慢来。首先给大家解释下,网上搜出的编码,多为Unicode字符集序号,而并非UTF-8编码,就像上图。如上节末尾所说,这两者之间有标准的对应关系。对于中文字符,UTF-8会用3字节表示,也就是
| Byte1 | Byte2 | Byte3 |
| 1110 xxxx | 10 xxxxxx | 10 xxxxxx |
以“招”为例,“招”的Unicode序号为62DB ,将其转化为二进制表示:
0110 0010 1101 1011
描述位不变,我们将化为二进制的Unicode序号填入前缀描述位(1110、10、10)为:
| 描述位 序号位 | 二进制码 | 十六进制码 |
| 1110 0110 | 1110 0110 | E 6 |
| 10 001011 | 1000 1011 | 8 B |
| 10 011011 | 1001 1011 | 9 B |
观察十六进制表示可得:E6 8B 9B,也就是“招”。同样的方式,序号8058代表“聘”。
四、总结
上面的一个小例子简单说明了编码转换的过程,对于其他编码也都是大同小异,大家有兴趣可以动手试试。总的来说,平日的乱码就是由于编码或解码方式不合适造成的,只要使用了正确的规则,乱码自然不乱了。至于口算,咳咳,复习下16以内加减法就行(手动微笑)。
