返回目录:excel表格制作

系列列表
"替代Excel Vba"系列(一):用Python的pandas快速汇总
请关注本号,后续会有更多相关教程。转发本文并私信我"python",即可获得按水平领域分类好的Python资料
前言
在本系列的上一章已经介绍了如何读写 excel 数据,并快速进行汇总处理。但有些小伙伴看完之后有些疑惑:
- 那只是简单读写数据而已,有时候需要设置 excel 的格式。
- 我用透视表不用写代码,两三下也可以弄出结果来。
今天,我就沿用上一章的数据,把需求升级一下,以解决上述疑点。
本文要点:
- 使用 xlwings ,设置单元格格式
- 使用 pandas 快速做高难度分组操作
注意:虽然本文是"Python替代Excel Vba"系列,但希望各位读者明白,工具都是各有所长,适合才是最好。

案例
数据与上一节一样,就一个学生的数据表。
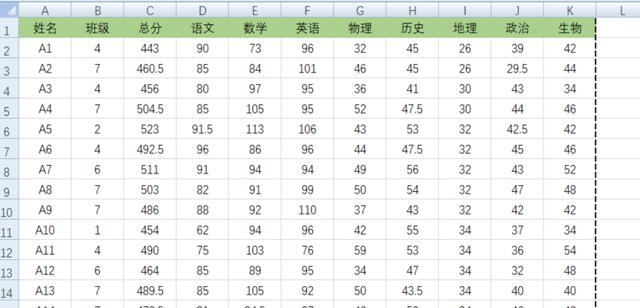
不过这次我们需要把每个班级成绩好的同学给揪出来好好表扬,因此条件如下:
- 找出每个班级的top 3 学生,在原数据表中以绿色底色标记
- 找出每个班级中低于班级平均分的学生,在原数据表中以红色底色标记
- 上述条件均以[总分]列为判断依据
导入包
本文所需的包,安装命令如下:
pip install xlwings
pip install pandas
脚本中导入
本文只说重点细节,至于如何从 excel 中读取数据,上一节已经有详细介绍。
排名
首先需要解决的是怎么得到班级 top 3? 首要任务是得到排名,如下:
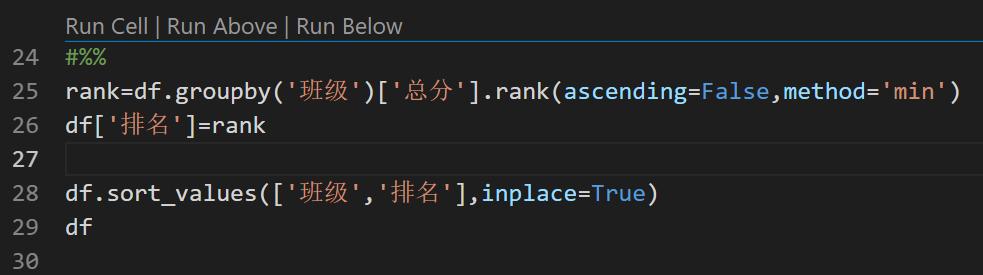
- 这里需要在数据中新增一列[排名]
- df.groupby('班级') 就是按 班级 分组的意思。
- df.groupby('班级')['总分'] 表示分组后每个组我们只使用[总分]这个字段。
- .rank(ascending=False,method='min') 是 pandas 中进行排名的处理。
- 参数 ascending=False ,表明需要以 [总分] 倒序做排名。
- 参数 method='min' , 表明如果有多个人有相同的总分,那么全部的人都用所有名次中最小的排名值。后面会看到数据。
- 此时显示变量 rank 的数据,可以看到结果就是排名结果(1列数据)
- 在 pandas 中往 DataFrame 中新增一列非常简单。 df['排名']=rank ,即可把排名结果放入表中新增的字段中。
- df.sort_values(['班级','排名'],inplace=True) ,按先[班级]后[排名]进行排序,不是必须的,只是为了方便查看数据。
- 参数 inplace=True ,表示直接在原有数据上操作,如果不设置这个参数,那么就需要写 df=df.sort_values(['班级','排名'])
来看看结果。
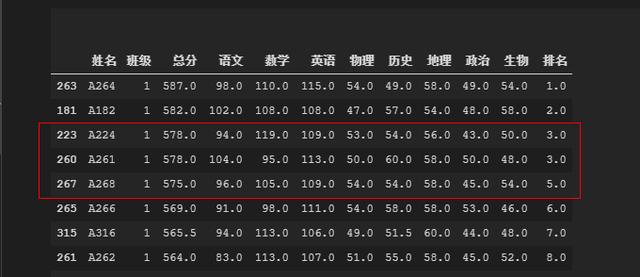
- 注意看第3和4行数据,他们是并列第3名。并且后面的人是从第5名开始。
找出低水平学生
现在找出低于所在班级平均分的同学吧。 先按班级计算平均分,然后把平均分填到每一行上。
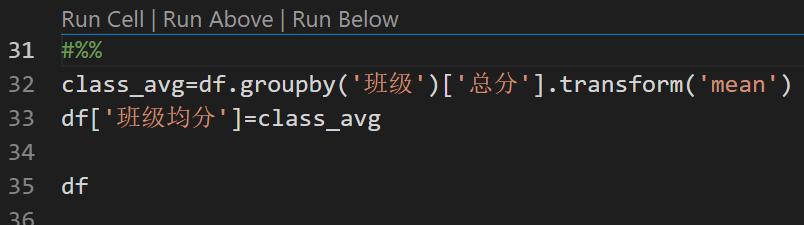
- df.groupby('班级')['总分'] 就不用说了,与上面的排名是一样的意思。
- .transform('mean') ,表示每组求平均。结果是每组都有一个分数。而 transform 方法的特点就是不会压缩原数据的行数,因此每组的数都是一样的平均分。
- df['班级均分']=class_avg ,同样新增一列。
看看数据
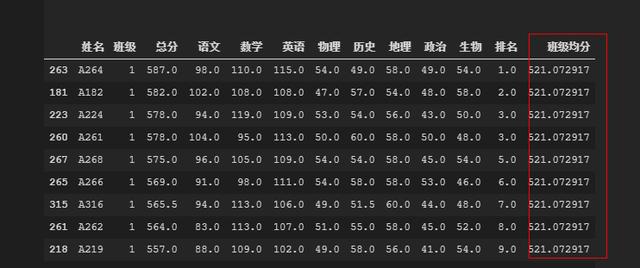
对于这里的 transform 方法可能有些小伙伴会不太理解。可以查看本号的相关文章,关注我噢。
万事俱备
看到这里,你可能会觉得很复杂,但注意,我们只是写了2句代码即可做到了比较复杂的分组汇总。
首先把 top 3的同学挑出来
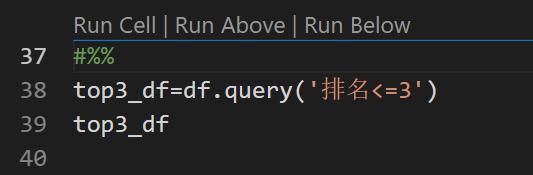
- df.query('排名<=3') ,过滤符合条件的记录。
接着把低于平均分的也挑出来
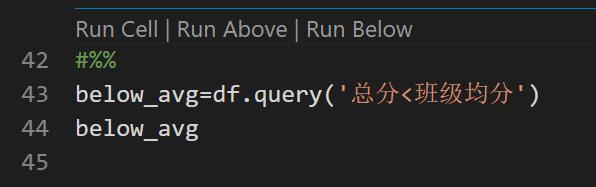
- df.query('总分<班级均分') ,过滤符合条件的记录。
但是,需求是需要我们在原表格上标记颜色。怎么可以用目前的结果数据关联到原数据上。
我们注意看得到的结果中的 index。就是最左边的那一列数字
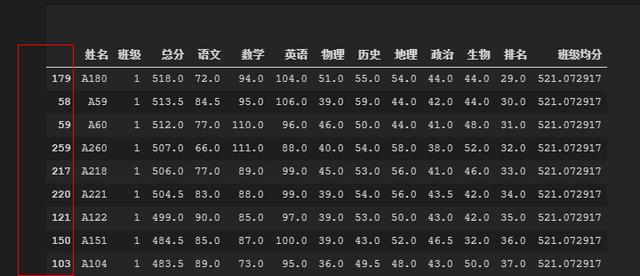
每个 DataFrame 都会有这样的 index,不管你怎么操作他,这个 index 都不会改变。因此我们可以利用 index 定位 excel 的单元格,然后通过 xlwings 标记底色就好了。
给表格加点颜色
首先定义一个设置颜色的方法
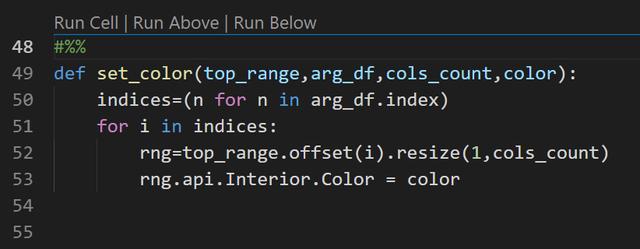
- indices=(n for n in arg_df.index) , 获得结果的索引值。
- rng=top_range.offset(i).resize(1,cols_count) ,定位需要设置颜色的行。
- rng.api.Interior.Color = color ,设置单元格底色。注意这里 .api 是因为 xlwings 是对 com 的封装,因此许多对象都提供了 api 这个属性,以便你能用 com 对象那套方法去操作。
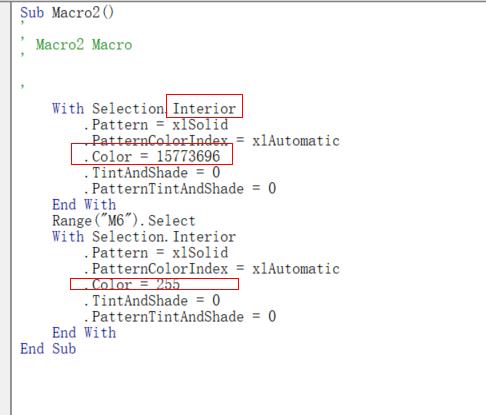
如果你对 excel 不熟悉,可能你会问,你怎么知道设置颜色是这些代码? 其实我是通过录制宏来得到。如下:
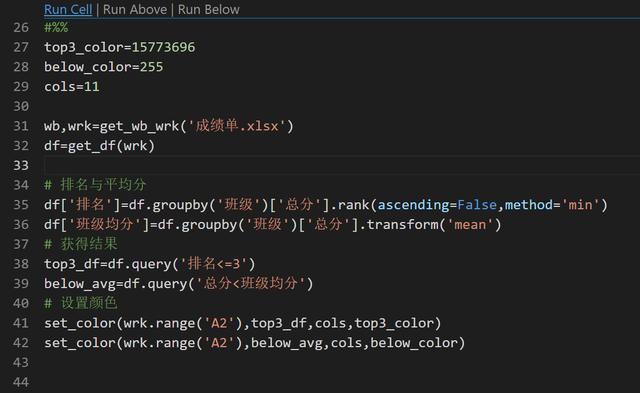
完整代码
以下是完整的代码:
本节就不再上 vba 代码了(没人愿意写~~)。
使用 pandas 到底好处是什么
目前为止,你可以看到 Python 处理 excel 数据的基本套路是
- 从 excel 中读取数据到 pandas 的数据结构中
- 使用 pandas 做各种处理
- 把结果回写到 excel 上
如果你熟悉 vba ,那么 pandas 就像一个数组+ sql 的多功能工具。
总结
通过本文应该可以解答之前的一些疑惑。像本次需求中的数据处理任务,即使你用透视表来解决也是不容易的,更不用说用 vba 了。 使用 python 不仅代码简洁易懂,并且整个过程都可以重复执行。
[源码地址](https://github.com/CrystalWindSnake/Creative/tree/master/python/excel_pandas/2)
请关注本号,后续会有更多相关教程。